
Optimizing Qwen Image for edge devices
Qwen Image is the largest open-weight state-of-the-art image generation model. With its 20B parameters, it poses unique challenges for Draw Things to support across iPhone, iPad, and Mac.

Draw Things supports local inference on iPhone, iPad, and Mac—including devices released as far back as five years ago.
Qwen Image is a 20B-parameter image generation model that delivers next-level prompt adherence. Qwen Image Edit is a fine-tuned variant with editing capabilities. At its core, the model is a 60-layer MMDiT transformer combined with a fine-tuned Wan 2.x video VAE (from Alibaba’s video generation model).
As discussed in BF16 and Image Generation Models, MMDiT tends to gradually increase the activation scale during training. This was already an issue for Hunyuan and FLUX.1, which contain only 20 and 18 layers of MMDiT blocks respectively. For Qwen Image, activations can reach magnitudes on the order of ~20 million.
On Apple hardware from the M1/M2 era, it is generally better to keep most computation in FP16 to avoid BF16 emulation. However, due to Qwen’s drastic increase in activation range, while main activations can still accumulate in FP32, far more FP16 activations need scaling than in earlier models.
Activation Dynamics
In each MMDiT block, two pathways feed activations back into the FP32 main path:
the
out_projresult after attention,and the
FFNresult.
For earlier models, only the FFN computation required scaling. In Qwen, later layers must produce sufficiently large activations in both pathways to influence the FP32 path—causing FP16 overflow unless scaling is applied.
To address this, we adopted a more aggressive down-scaling strategy:
The input to
q/k/vprojection is down-scaled by 8 (with RMS norm epsilon adjusted accordingly).The attention output is further down-scaled by 2, then up-scaled back after
out_projinto the FP32 main path.For the FFN, we use a 32× down-scale factor for layers 0–58, and an even more aggressive 512× factor for layer 59.
With these strategies, we can run both Qwen Image and Qwen Image Edit in FP16 with minimal accuracy loss. A BF16 version is also provided, allowing only the critical layers requiring scaling to run in BF16 without scaling—minimizing the impact of BF16 emulation on older devices.
Read this post for a comparision of the activation scaling impact.

Video VAE
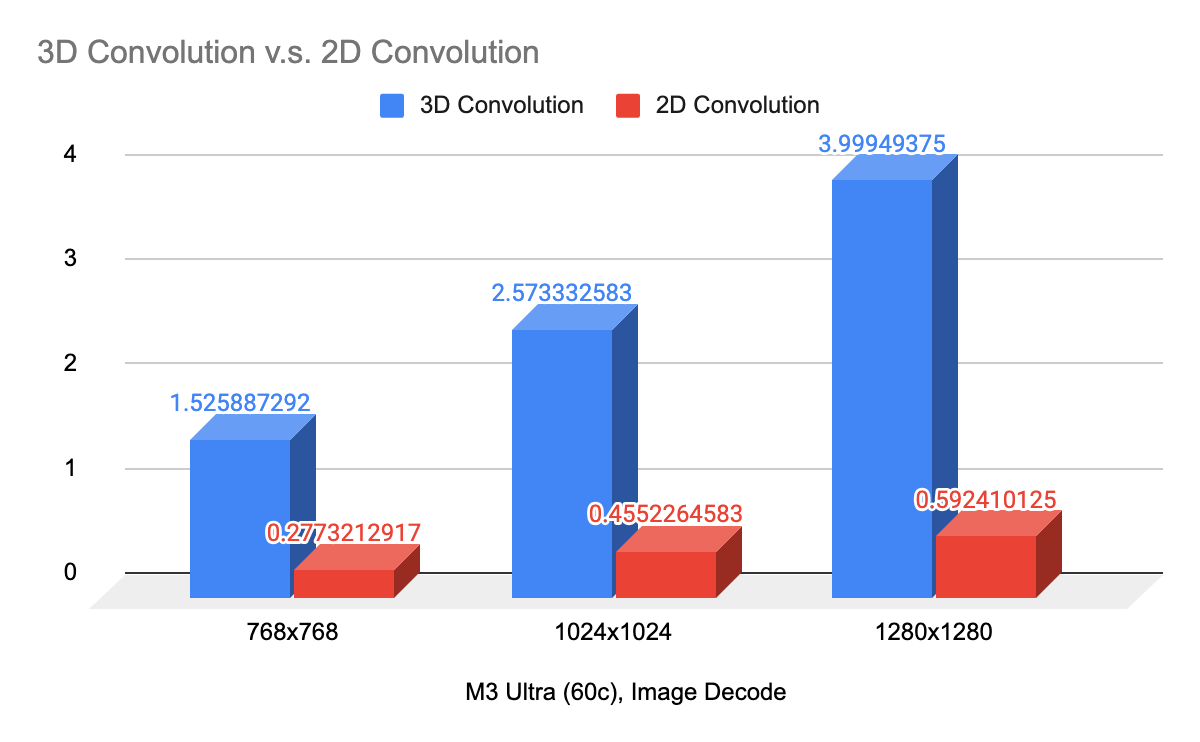
Qwen Image uses Wan 2.x’s video VAE to encode and decode latent space. Like FLUX.1’s VAE, it has a similar parameter count, but it employs causal 3D convolution for many operations. Naively applying the video VAE for first-frame decoding makes image generation slow: decoding a 1024×1024 image can take 5–6 seconds on an M3 Pro.
Looking deeper, however, Wan’s video VAE applies zero padding for previous frames during first-frame decoding. In these cases, full 3D convolution is unnecessary. By adjusting convolution weights/biases and switching to 2D convolution, we reduce decoding time to under a second for the same resolution.
Timestep-based Adaptive Layer-Norm
Of Qwen Image’s 20B parameters, about 7B are allocated to adaptive layer norm. In our SD3 optimization article, we described splitting the model to save VRAM. Unlike FLUX.1 or Hunyuan (which also use adaptive layer norm with MMDiT), Qwen Image’s adaptive layer norm depends only on the timestep.
This leads to an interesting implication: if we discretize timesteps between 0 and 1000, we only need to store 1001×718×3072 possible values, a lower number than the ~7B parameters required to generate them. In reality, timesteps in flow-matching models are not strictly discrete, but practitioners often fix the number of steps and shift values. By caching these projected conditions, we can avoid loading ~7B parameters into memory.
Note: This optimization isn’t necessary when the weights already reside in VRAM—the incremental FLOPs are minimal. It primarily helps when loading ~7B parameters into RAM is the bottleneck.
hi, how does the scaling been done. Is there some code tips? Will u release the model b.t.w. Thanks a lot.