
From iPhone, iPad to Mac - enabling rapid local deployment of SD3 Medium with s4nnc

SD3 Medium was released on June 12th, 2024. Like everyone else, we gained access to the model on the same day. From then on, it is a race to deploy the said model to Draw Things users on iPhone, iPad and Mac. In this post, I will outline the tools we used, the lessons we learned, and the unique optimizations we applied to ensure the best-in-the-class performance across a broad range of Apple devices.
Model Conversion
Over the past year, we’ve significantly streamlined our model conversion workflow. What used to take weeks with Stable Diffusion 1.4 now takes about a day. For example, we implemented our FP16 version of SD3 Medium on June 13th, 24 hours after the release.
To deploy cutting-edge image/text generative models to local devices, we use Swift implementations that compile natively on these platforms. This involves translating Python code, typically written in PyTorch, into Swift. We begin this by setting up the correct Python environment, creating minimal viable inference code to correctly call the model, inspecting the result, and then implementing the Swift code.
PythonKit has been essential for our conversion work, allowing us to run Python reference code directly alongside our Swift reimplementation. The first-class support of s4nnc on CUDA systems also enables us to run our Swift reimplementation on Linux systems with CUDA, which is often the most hassle-free environment for running PyTorch inference code.
Our reimplementation generally involves rewriting the PyTorch model into a more declarative Swift model and comparing outputs layer by layer. This is particularly straightforward with transformer models, where each layer follows the same architecture.
Our implementation: https://github.com/liuliu/swift-diffusion/blob/main/examples/sd3/main.swift#L502-L661
SD3 Ref: https://github.com/Stability-AI/sd3-ref/blob/master/mmdit.py#L11-L619
Model Quantization
Deploying large models to local devices often requires weight quantization. For image generative models, we carefully balance quality and size trade-offs. With Draw Things, we ensure all our quantized models are practically “lossless.” We focus on sensible reductions that maintain compatibility across a wide range of devices rather than pushing for the smallest possible model size.
Currently, s4nnc supports limited quantization options, including 4-bit, 6-bit, and 8-bit block palletization as our main schemes. For diffusion models, we use the mean squared error metrics of the final image between quantized and non-quantized models to guide our decisions. We selected 8-bit quantization for SD3 Medium and 6-bit for the T5 encoder.


Model Optimization
Unlike the UNet in SDXL/SD v1.5, SD3 Medium uses straightforward transformer blocks, limiting optimization opportunities — especially regarding FLOPs. However, we managed to split the model to reduce peak RAM usage during the diffusion sampling process to approximately 2.2 GiB for the quantized model (around 3.3 GiB for the non-quantized model).
This is possible by observing that while adaptive layer norm blocks are minimal in FLOPs, they have a high parameter count, around 670M. Since the input for the adaptive layer norm includes timestep conditioning, we cannot reduce FLOP computation. However, since there are no dependencies on model intermediate activations, we can batch the adaptive layer norm computation of every timestep to the beginning of diffusion sampling all at once, converting matrix-vector multiplication to matrix-matrix multiplication, which is slightly more efficient.
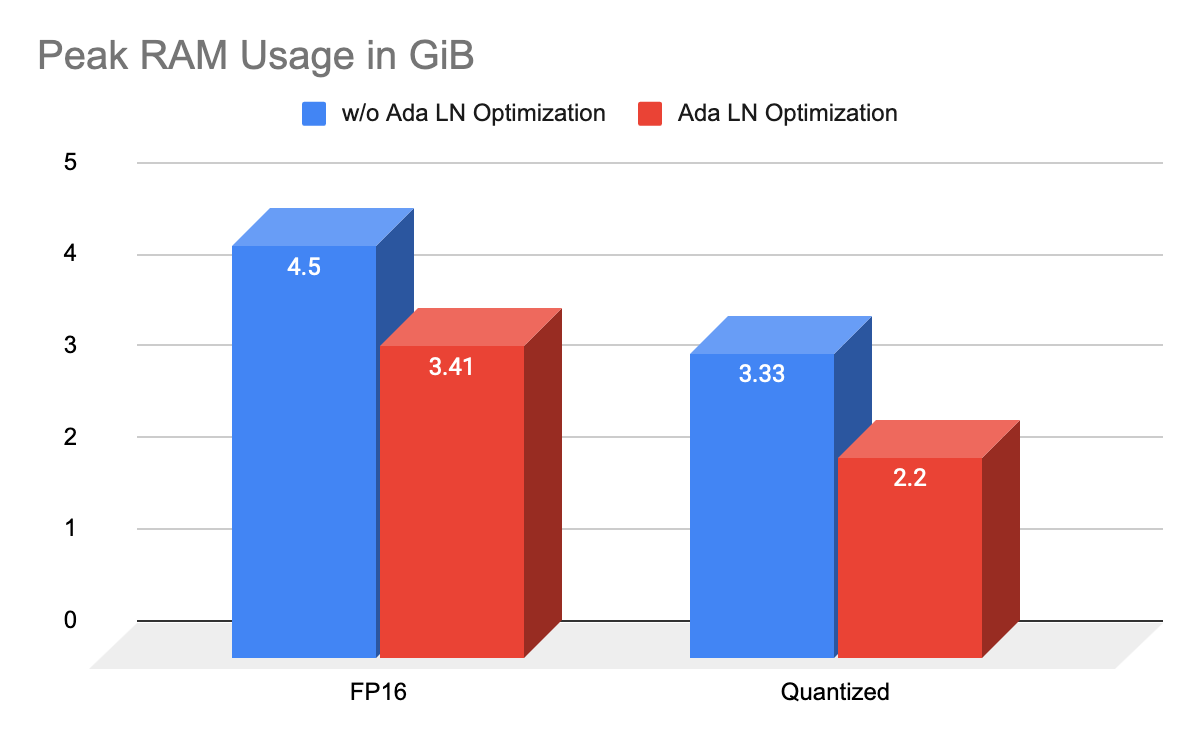
Thanks to these optimizations, we implemented the fastest SD3 Medium model inference on macOS, iOS, and iPadOS systems with minimal RAM usage and successfully shipped it to real users within a practical app.

Future Directions
Our implementation can provide valuable feedback into the training process. Moving forward, we aim to conduct more research and ablation studies to explore:
1. Optimal parameter count distribution for adaptive layer norm — could we allocate fewer parameters here, and more to MLP/QKV projection?
2. Comparing more quantization schemes to identify per-layer improvements and establishing an unbiased prompt dataset for the future data-free fine-tuning.
3. Leveraging torch.compile to rewrite the PyTorch model in Swift, all from within Swift using PythonKit.
We are excited to continue our research and share our development work in the future.