
Metal FlashAttention 2.0: pushing forward on-device inference & training on Apple silicon

Metal FlashAttention underpins Draw Things’ claim of fastest image generation inside the Apple ecosystem. It conserves system memory, it is fast and it supports a wide-array of devices with the oldest being iPhone 12 from more than 4 years ago.
Back in September, Philip Turner and I released Draw Things with Metal FlashAttention 2.0. Since then, we’ve integrated not only the forward pass (useful for inference) but also the experimental backward pass (useful for training). Combining together, Draw Things is the only efficient application on macOS / iOS that supports both inferencing and fine-tuning FLUX.1 [dev], a 11B-parameter, state-of-the-art image generation model. This major version upgrade delivers:
Up to 20% faster inference on newer hardware such as M3 / M4 / A17 Pro;
Carefully tuned memory precision / register precision choices to make FP16 inference more accurate and less prone to NaN errors;
Backward pass implementation that is up to 19% faster than naive implementations to support efficient training on Apple devices;
Better tuned parameters to deliver efficient inference and training for larger head dimensions;
Switch to runtime code generation for better compiler compatibility and ease-of-integration;
Support of BFloat16 emulation, with a slight deviation from certain rounding rules to run more efficiently on older devices;
Keeping performance consistent with a wide-array of sequence lengths and head dimensions (minimal performance cliffs).
Translating these gains into real-world numbers, we see up to 20% improvement on inference for FLUX.1 models on M3 / M4 devices, up to 20% improvement on inference for SD3 / AuraFlow models on M3 / M4 devices. Similar improvements for SD3 / AuraFlow for older hardware and around 2% improvement on older hardware for FLUX.1 models.
Compared to other implementations, FLUX.1 integrated inside Draw Things is up to 25% faster than mflux implementation on M2 Ultra for each iteration, and more for end-to-end times; it is up to 94% faster than ggml implementations (also known as gguf format). SD Large 3.5 integrated inside Draw Things is up to 163% faster than DiffusionKit implementation for each iteration (on M2 Ultra).


mflux: 0.5.1, DiffusionKit: 0.5.2, mlx: 0.21.1, ComfyUI: v0.3.8+PyTorch v2.6.0.dev20241218
On the training side, training SDXL LoRA at 1024x1024 now is 2% faster than our previous implementation in Balanced mode. There is no comparison for training FLUX.1 LoRAs on macOS, our implementation scores 9s per step per image at 1024x1024 resolution on M2 Ultra.
With the release of Metal FlashAttention 2.0, we invite the community to collaborate and extend this implementation to more downstream frameworks. Our reference Swift implementation is available at: https://github.com/philipturner/metal-flash-attention. Our C++ implementation is available as part of ccv: https://github.com/liuliu/ccv/tree/unstable/lib/nnc/mfa.
Appendix
Comparison with other SDPA (Scaled-dot Product Attention) kernel implementations (MLX, Apple MPSGraph). See raw data at https://docs.google.com/spreadsheets/d/1NHzYHcqtH5xb18trn9NyTc1EeSfXZen9C7E7vsPb_lI/edit?usp=sharing

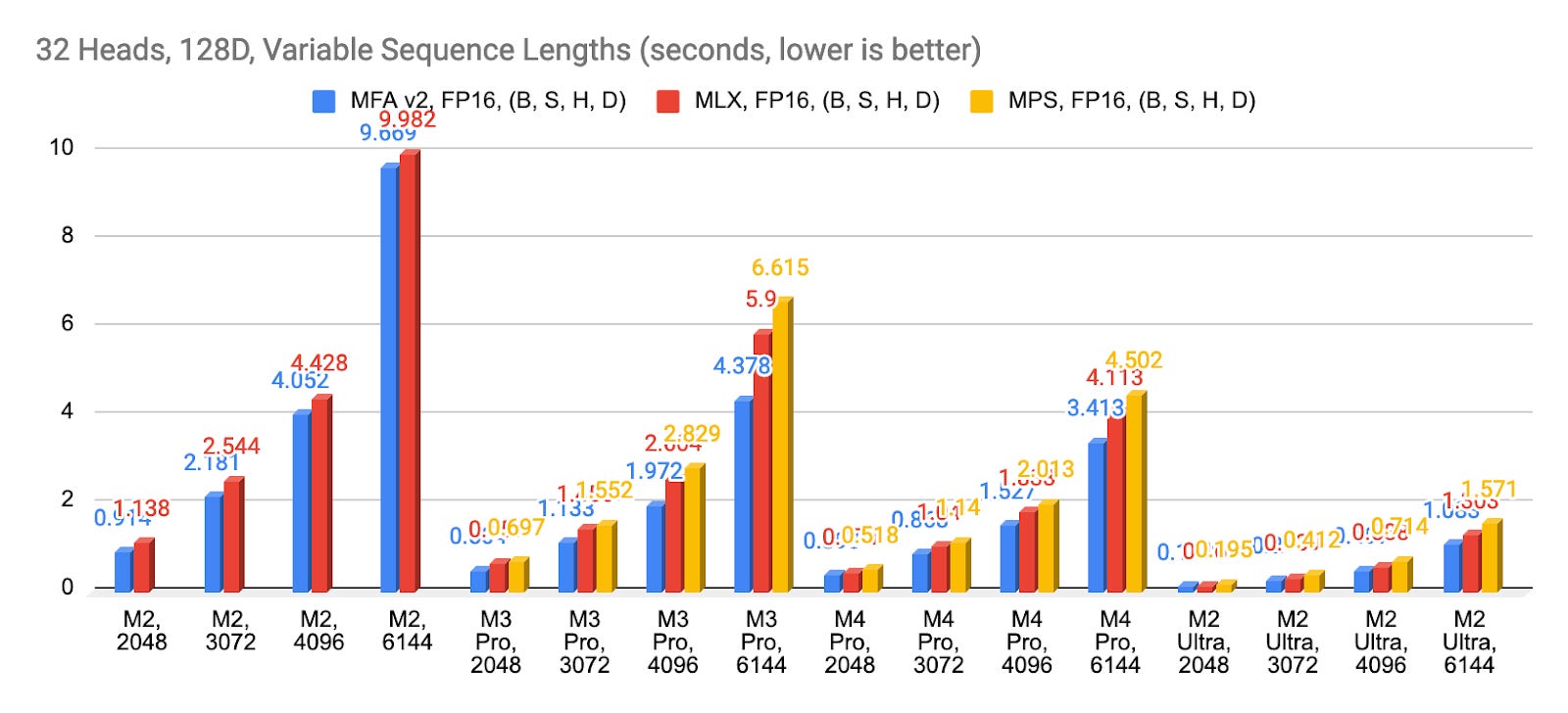
End-to-end benchmark data is available at https://docs.google.com/spreadsheets/d/1A8xC2_wh_Nwc5p2uvNMnKMtN4kkJac1E764XHrADpBs/edit?usp=sharing