
Integrating Metal FlashAttention: accelerating the heart of image generation in the Apple ecosystem

Draw Things was the first practical app to run full-blown image generation models at the “edge” — directly on your mobile phone. Since its introduction, there’s been growing interest in locally-run open-source large models. LLaMA.cpp brought large language models to the laptop; MLC LLM executed language and image generation models in web browsers. What began as an academic exercise has evolved into a movement: just let me run my model, as powerful as the cloud ones, locally and free (“as in freedom”)!
Until now, most algorithmic innovations and improvements have occurred on NVIDIA CUDA hardware. It makes sense when most AI-related computing happens on server-side. However, as we move the compute closer to the edge, how to drive the same algorithmic innovations and improvements to one of the most used hardware platforms captured our imagination.
Over the past few months, Philip Turner and I worked closely to integrate his Metal FlashAttention into the Draw Things app. With version 1.20230807.0 of the app, it generally cuts the image generation time by half, often bringing superior experience than the cloud, with added benefits of privacy and freedom.
Metal FlashAttention
Metal FlashAttention comprises Metal compute shaders optimized for operations commonly found in large image generation and language models. That includes thin matrix multiplications (e.g. [4096, 320] x [320, 320]), scaled dot product attention (the heart of multi-head attention or transformers) and layer normalization. It stands as an open-source alternative to Metal Performance Shaders (MPS).
GEMM
GEMM computations, typically found in the Stable Diffusion variant of models (v1, v2, XL), don’t hit the sweet spot of Apple’s Metal Performance Shaders or MPSGraph implementation. Metal FlashAttention leverages the simdgroup_async_copy API (since A14), an undocumented hardware feature that overlaps compute and load instructions.

FlashAttention
Inspired by the FlashAttention project, Metal FlashAttention aimed to improve both latency and memory footprint. At the core, it is pretty easy to understand why: scaled dot product attention is concisely demonstrated by the two lines of code from the PyTorch documentation:
attn_weight = torch.softmax(scale * (Q @ K.transpose(-2, -1)))
return attn_weight @ VThere’s no need to to materialize the full Q @ K.transpose(-2, -1) matrix before computing the final result. Naively, you simply need one-row per Q @ K.transpose(-2, -1) to compute softmax and then do the final matrix multiplication. This approach, often referred to as attention slicing, has been attributed to the further performance improvements in apple/ml-stable-diffusion (named as SPLIT_EINSUM_V2).
The original FlashAttention in CUDA (by Dao AI Lab) focused on both forward and backward pass. Metal FlashAttention paid particular attention to the forward pass (inference). We made several optimizations to the original FlashAttention on the inference path, some of these optimizations are concurrently adopted in the FlashAttention v2 release. These optimizations decreased the total number of computations and increased numerical stability. We also made a unique block-sparse algorithm that automatically detects sparsity in the attention matrix. This approach allowed a single shader to handle sparse, causal, or irregular masks, especially masks that change dynamically at runtime.

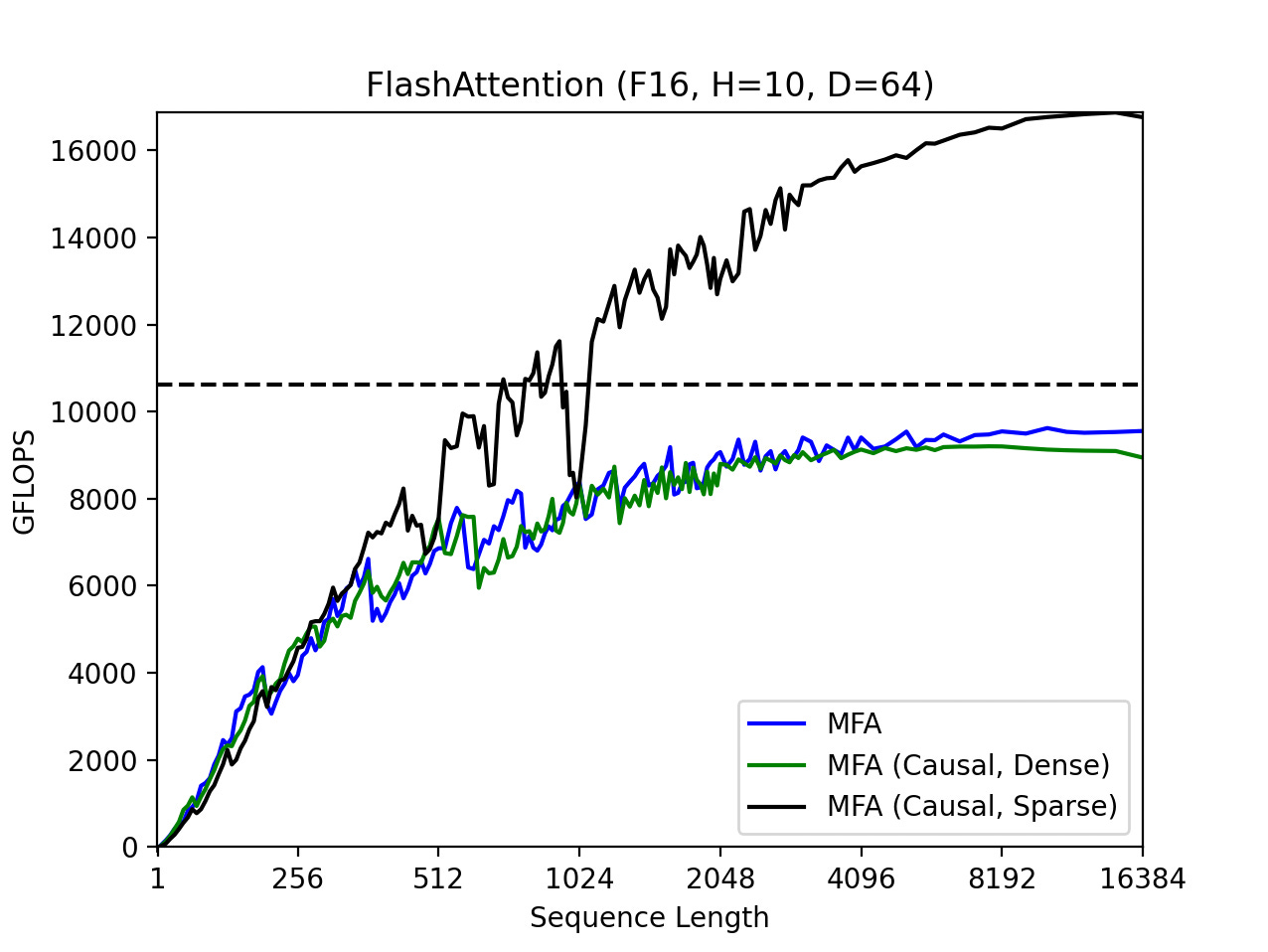
The resulting speedup is not just measurable in percentages — it represents orders of magnitude. In the bottom graph, MPS performance was excluded as it couldn’t complete the benchmark in a reasonable time frame. It maxed out at 2000 GFLOPS (top), while MFA soared an order of magnitude higher (bottom).
Real-world Impact
The GEMM kernel of Metal FlashAttention has been integrated into the 1.20230726.0 release of the Draw Things app. The community has confirmed our claim of 10-30% performance improvements over many devices.
The full Metal FlashAttention integration, including GEMM with fused bias, scaled dot product attention with fused multi-head output projection, and custom layer normalization has gone through extensive testing & benchmarking.


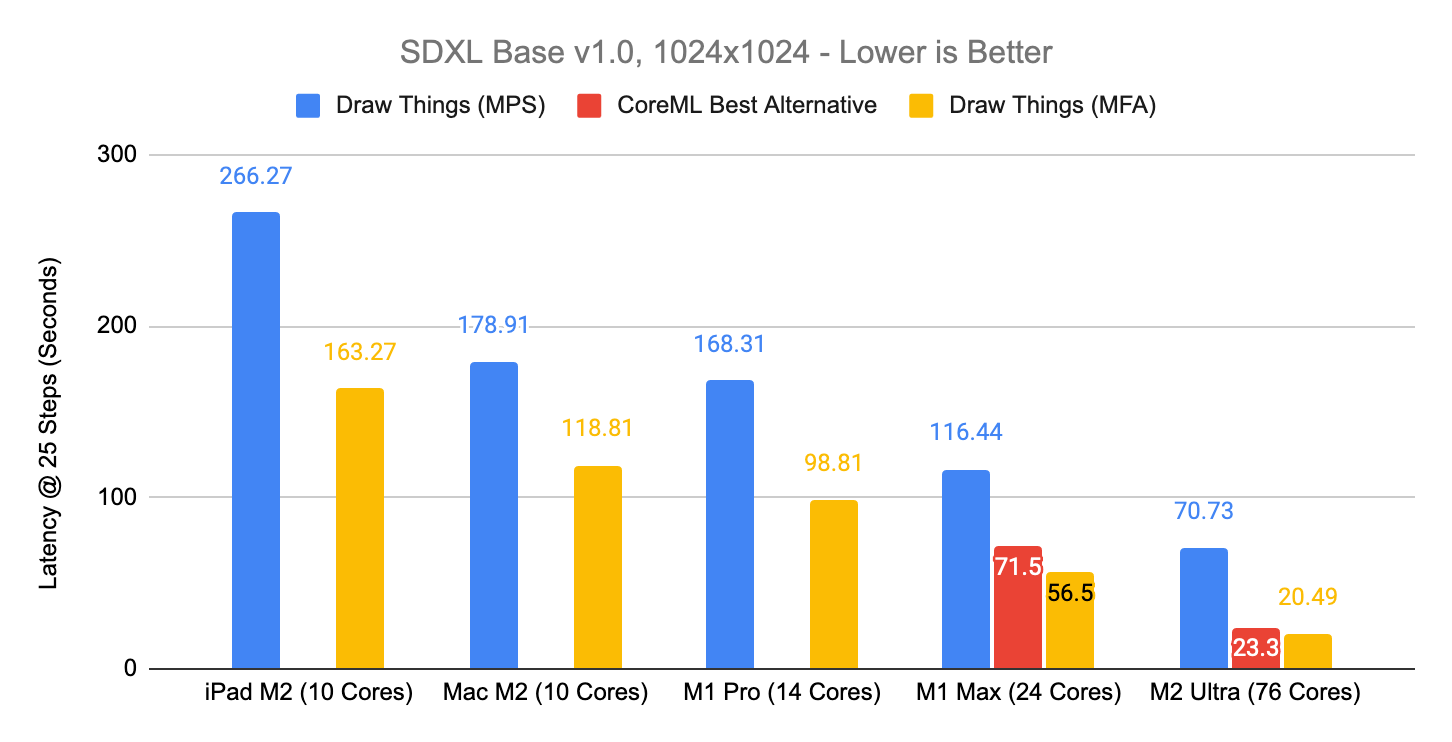
Comparing w/out Metal FlashAttention, image generation latencies are roughly halved (43–120% faster). This speedup is consistent across a wide range of Stable Diffusion architectures, several device families (iPhone 12 and above, M1 and above) and every image resolution.
Comparing to CoreML implemented Stable Diffusion v1.x, v2.x with Apple Neural Engine, GPU-accelerated Metal FlashAttention slightly trailing behind ANE performance on M1 / M2 base model (~12.8s with ANE and ~15.2s with MFA, at 25 steps, 512x512) while outperforms them on M1 Pro / M2 Pro and above. With the v2.0 model on A16 chip (Stable Diffusion v1.x with CoreML cannot be run on iPhones without quantization), MFA trailing behind ANE performance (~26.3s with ANE and ~34s with MFA at 25 steps, 512x512) by ~22%.
Comparing to CoreML implemented Stable Diffusion v1.x, v2.x and XL with GPU, Metal FlashAttention outperforms in wider margin on M1 Pro / M2 Pro and above models (usually around 20% to 40% faster than CoreML GPU, ORIGINAL configuration). CoreML GPU implementation outperforms ANE implementation on these devices.

Metal FlashAttention is the kind of optimization that raises the tide for us all. Unlike our CoreML integration, Metal FlashAttention improves performance across all image generation resolutions and with any given prompt length, Whether dealing with the standard 77-token prompt or thousands of tokens prompt, every workflow benefits from Metal FlashAttention’s integration. By integrating into our low-level framework directly, there is no first-time-model-loading cost, nor first-time-model-conversion cost associated with CoreML or other alternative runtimes.
Above comparisons were done with Swift CoreML Diffusers app from macOS App Store (v1.1), with the exception of A16 performance (done with the CoreML implementation inside Draw Things app). SDXL comparison was done with Diffusers app built from source (commit: 4eab4767) with Xcode 15 beta 5 on macOS Sonoma beta 5, Release configuration, with FP16 SDXL Base CoreML model. Diffusers on iPad was built from source (commit: 4eab4767) with Xcode 14.3.1, Release configuration. Preview and Safety Checker were disabled. Both are measured with minimum of the 2nd and 3rd run, with Preload On in Draw Things (with exception of A16 / iPhone 14 Pro (too little RAM to preload the models). iPad Pro M2 is a 8GiB configuration so the Preload is automatically off for SDXL). All measurements are done with 25 steps.
Above comparisons were done with following hardware specs: Mac M2 refers to Mac Mini M2 with 16GiB RAM and 10 GPU cores. M1 Pro refers to MacBook Pro M1 Pro with 16GiB RAM and 14 GPU cores. M1 Max refers to Mac Studio M1 Max with 32GiB RAM and 24 GPU cores. M2 Ultra refers to Mac Studio M2 Ultra with 192GiB RAM and 76 GPU cores.
Sprinting Forward
With Metal FlashAttention integrated into the Draw Things app, and our community enjoys faster image generation time, we’re eager to see Metal FlashAttention get integrated into many other applications and frameworks to empower local inferences from image generation models to large language models in the Apple ecosystem.
The Metal FlashAttention project, authored by Philip Turner and sponsored by Draw Things, is open-source and can be found at https://github.com/philipturner/metal-flash-attention under MIT license.