
Making Apple Neural Engine work in a custom inference stack
Apple Neural Engine always looked appealing on paper, but using it inside a custom runtime was harder. In 1.20260410.1, we made ANE practical for 8-bit S models by using CoreML only as an accelerator.

Apple Neural Engine has always been an interesting piece of hardware for local inference on Apple devices. The challenge, for us, was never whether ANE could run neural networks. The challenge was whether it could be made useful inside a custom inference stack, where we manage intermediate allocations, kernel caching, and inference scheduling ourselves.
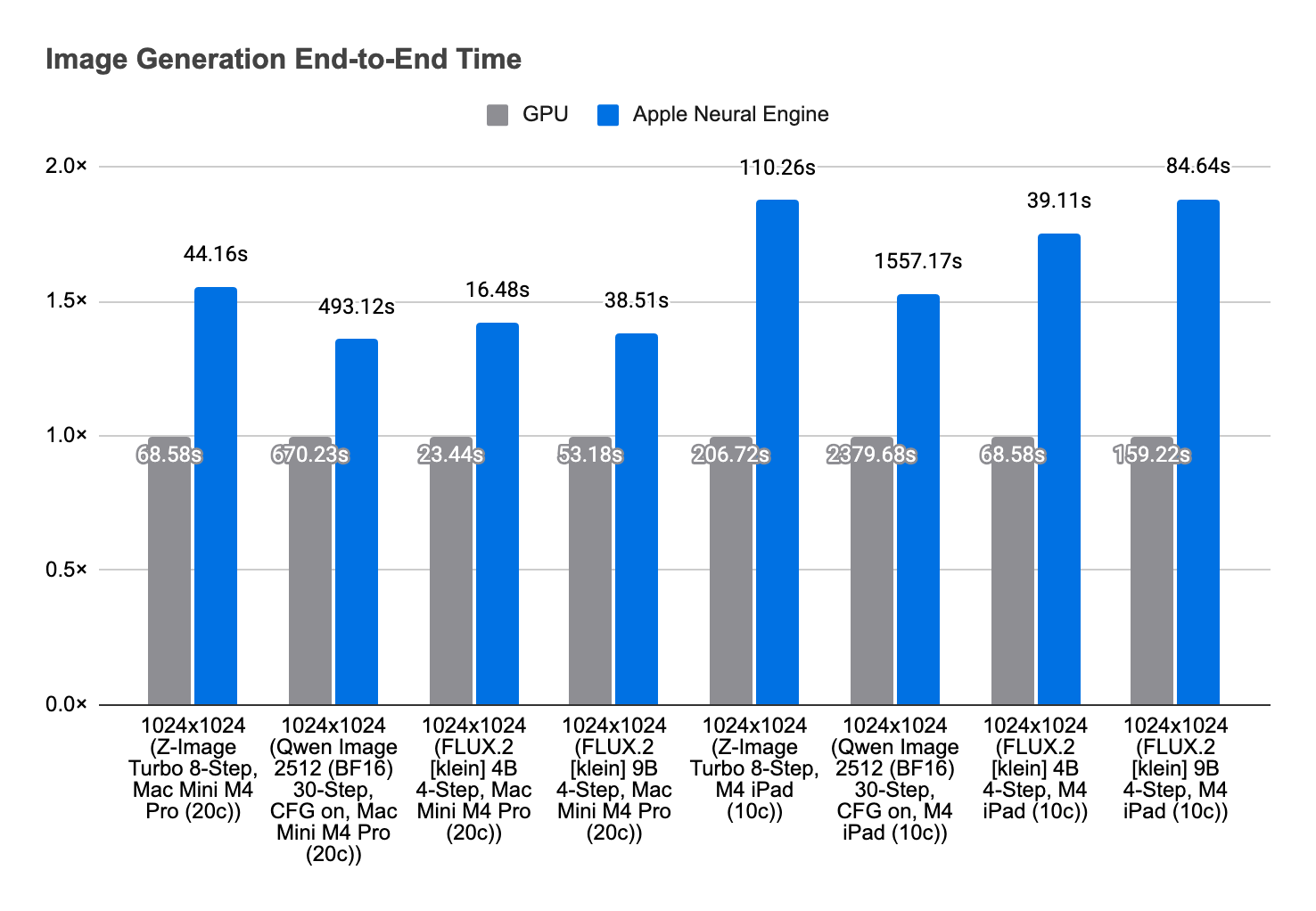
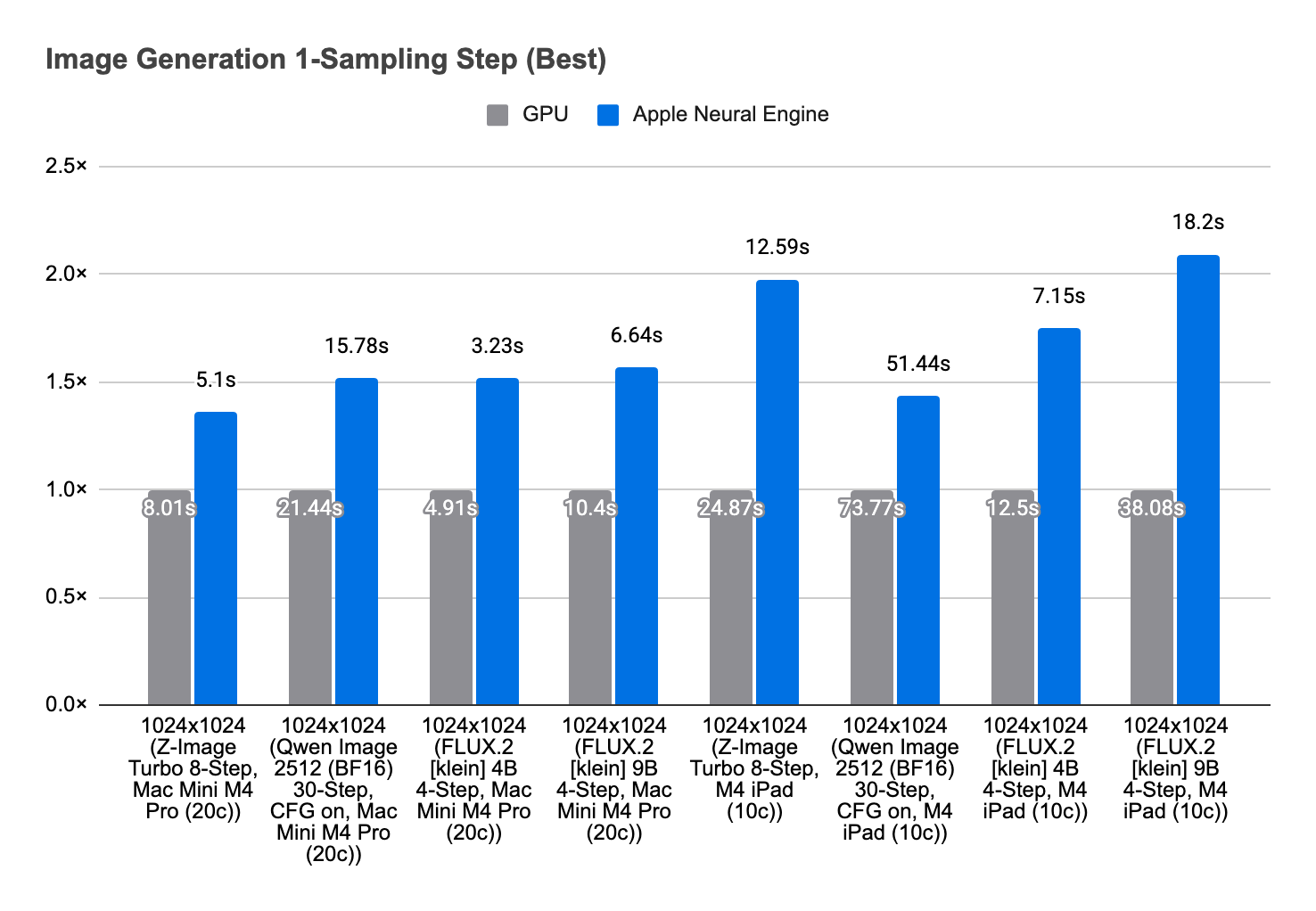
In Draw Things 1.20260410.1, we shipped Apple Neural Engine support for 8-bit S models on M3 and M4 devices. On M4, this can deliver up to 1.8× speed-up. On M3, M4, and M5, it can also reduce energy usage and run cooler. The key change is that CoreML no longer owns end-to-end inference. Instead, we use it as an accelerator for selected operations inside our own runtime.
That distinction matters.
We already supported CoreML inference in Draw Things for older models such as Stable Diffusion 1.5. That path compiled the full PyTorch model through coremltools into an mlpackage, then delivered the compiled mlmodelc to the device and let CoreML execute the whole graph. It works, but it also comes with limitations that are hard to ignore for our use case. In practice, it is tied to fixed shapes, flexible shape support has some buggy behaviors that we never shipped, and the first model load can take anywhere from 20 to 50 seconds. For SD 1.5 at 512x512, a roughly 600M-parameter model can also require 3 GiB to 4 GiB of scratch RAM.
None of that is especially attractive when the target is no longer a fixed-shape 512x512 Stable Diffusion deployment, but a much larger model and a runtime that wants to invoke ANE many times in a fine-grained way.
The old design compiled the full model into a CoreML program. The new design does almost the opposite: we only compile matrix multiplication programs into CoreML, and invoke them from inside our own inference stack. That lets us keep control over memory management and scheduling, but it also raises a practical question: is ANE fast enough to pay for the overhead of many fine-grained invocations?
Until recently, the answer was no.
On macOS 26 and iOS 26, CoreML can finally accept int8 arrays directly. That matters quite a bit for this design. Before that, feeding data into a CoreML program often meant promoting int8 values to fp16 or int32 first, which can double or quadruple the memory footprint of the transferred data. CoreML execution also ultimately happens out of process, so once these invocations are repeated many times in one inference, cross-process traffic becomes a real cost. For this architecture to make sense, the accelerated operation has to be fast enough to overcome that overhead.
8-bit S is our format for int8 weights with row-wise scale factors. On ANE, int8 matrix multiplication is also the only path that gets close enough to the advertised 38 TFLOPs throughput to make this architecture worthwhile. Put differently, direct int8 handoff support in macOS 26 / iOS 26 made the invocation model practical, and int8 matmul performance made it worth doing.
We explored a few configurations to see what the right integration should be.
One option was to use the private ANE API. It can do some interesting things, and in particular it opens the door to designs with no disk writes for baked-in weights. We were able to get the convolution kernel working, and it can reach peak performance. But that path ultimately was not right for us. The weights are effectively baked in, and there is no workable path for the kind of dynamic weight handling we need. The risk of relying on a private API was not justified by that design.
The more practical path was to stay on public APIs and give CoreML a much narrower role.
With dynamic matmul, we can avoid baked-in weights and still reach around 22 TFLOPs without batching or other tricks. That is good enough. Combined with direct int8 array support, and with IOSurface used to reduce the overhead of moving data in and out, this gives us a shape that fits our runtime much better: no private APIs, no need to let CoreML take over the full graph, and no need to give up control of intermediate memory and scheduling.
That is the architecture we shipped.
With this implementation, Apple Neural Engine becomes an accelerator inside our custom inference stack rather than the owner of the end-to-end inference process. We manage the intermediate allocations. We manage kernel caching. We manage scheduling. CoreML is there to execute the operations where ANE is useful, not to dictate the whole runtime structure.
ANE now works for our 8-bit S models on M3 and M4 devices, where we enable it for faster image generation. On M5, we also support it as an option for lower energy consumption, even if the absolute generation time is a bit longer than the GPU path.
We wanted ANE as an accelerator inside our own inference stack. That was not practical before 8-bit S. Now it is. And on M3 and M4, that means faster and cooler generations for you to enjoy.
The actual implementation is available, as always under open-source license for others to build upon.