
2 Days to Ship: Codex-authored Metal Compute Shaders in Draw Things
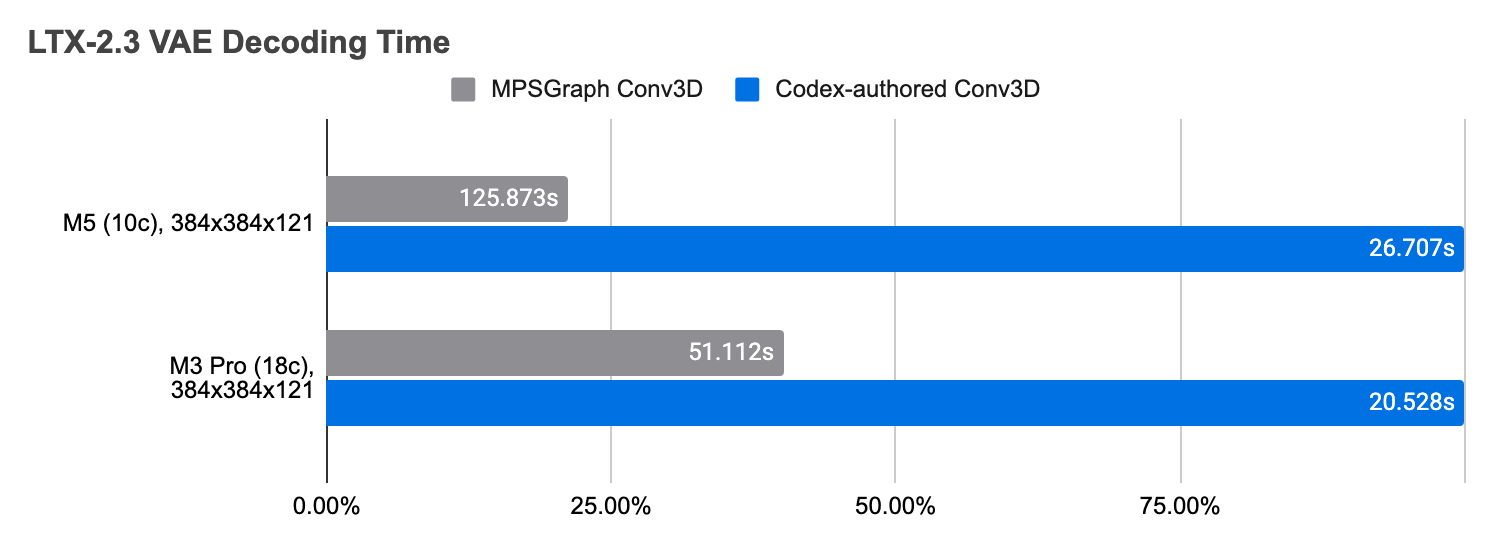
In the 1.20260314.0 release, we shipped our first two Codex-authored Metal compute shaders, which improved LTX-2.3 video VAE decoding speed by about 2.4x on M1 through M4, and 4.7x on M5.

This is not a post about the nitty-gritty details of the journey. The whole episode took 2 days. This is a short post, more along the lines of: “It is here. Get used to it.”
In the 1.20260314.0 release, we shipped our first two Codex-authored Metal compute shaders, which improved LTX-2.3 video VAE decoding speed by about 2.4x on M1 through M4, and 4.7x on M5. On their own, the shaders delivered 4x and 8.3x speedups over the MPSGraph baseline, respectively.
3D convolution is one of those operations that had its day in the past. These days, much of its usefulness has been diminished by the rise of transformer architectures. But for video generation, 3D convolution is still a handy little tool for mixing information across time. There are other ways to do it, but it is handy, readily available, and well optimized on NVIDIA platforms.
It is also supported on Apple platforms, at least since 2022, through the MPSGraph API. In Draw Things, we use that API to support 3D convolutions for the video VAE decoders of video diffusion models such as Wan 2.x and LTX-2.x. We always knew we could probably do better ourselves, but it was never a priority.
Until LTX-2.3.
LTX-2.3 updated its video VAE to improve reconstruction fidelity. The new decoder is deeper, and therefore requires more FLOPs to complete. On M5, our old LTX-2.3 video decoding pipeline could take as long as the entire diffusion process combined.

In the experimental repo, Codex quickly gave us some initial numbers. The MPSGraph 3D convolution API could only reach about 1.1 TFLOPs, far below the roughly 12 TFLOPs we can achieve with our GEMM kernel on M5. Further analysis with Metal Frame Capture showed that the MPSGraph 3D convolution code path was not using the neural accelerator.
After that, the breakdown for how Codex should approach the problem was straightforward:
Give it access to the Metal Shading Language Specification PDF, and ask it to implement 3D convolution using the new 2D convolution tensor ops API.
Ask it to write unit tests to verify the results.
Give it development access to an M5 iPad so that it can benchmark the initial kernel.
Give it access to our old GEMM kernel so that it can understand the optimization target, namely reaching FLOPs parity.
There was some back-and-forth on how padding should be supported, but by the end of March 12, we had shipped a build with a Codex-authored, neural-accelerator-enabled 3D convolution shader to TestFlight testers.
I used that time to do a bit more research on the topic and found the MLX PR discussing the use of implicit GEMM to implement 3D convolution. The concept is similar to how we do that for 2D convolution. The next day, I gave Codex the PR link, our GEMM kernel implementation, and asked it to implement 3D convolution on an M3 Pro using implicit GEMM. Since we already had pretty good test coverage, Codex more or less auto-piloted to the finish line with a shader that quickly came within 10% of FLOPs parity. That was already 4x the performance of the MPSGraph implementation.
From there, I migrated the session to an M2 Ultra and asked Codex to benchmark it there and continue optimizing if needed. It initially showed some inefficiencies on M2 Ultra, which has more GPU cores, but Codex was able to ramp performance up quickly from about 10 TFLOPs to about 20 TFLOPs.
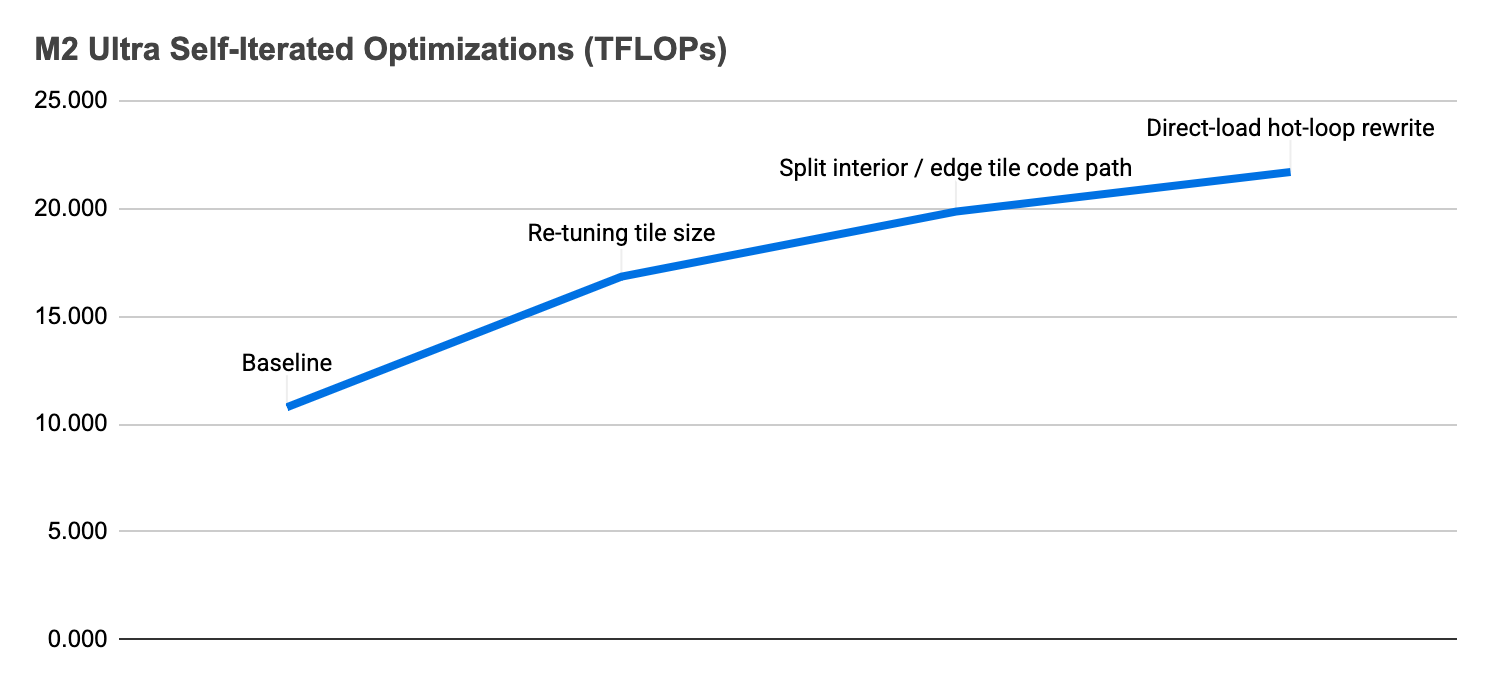
The build with the new optimized 3D convolution compute shader for pre-M5 devices went out to TestFlight on Friday. Today, we released it to the public.
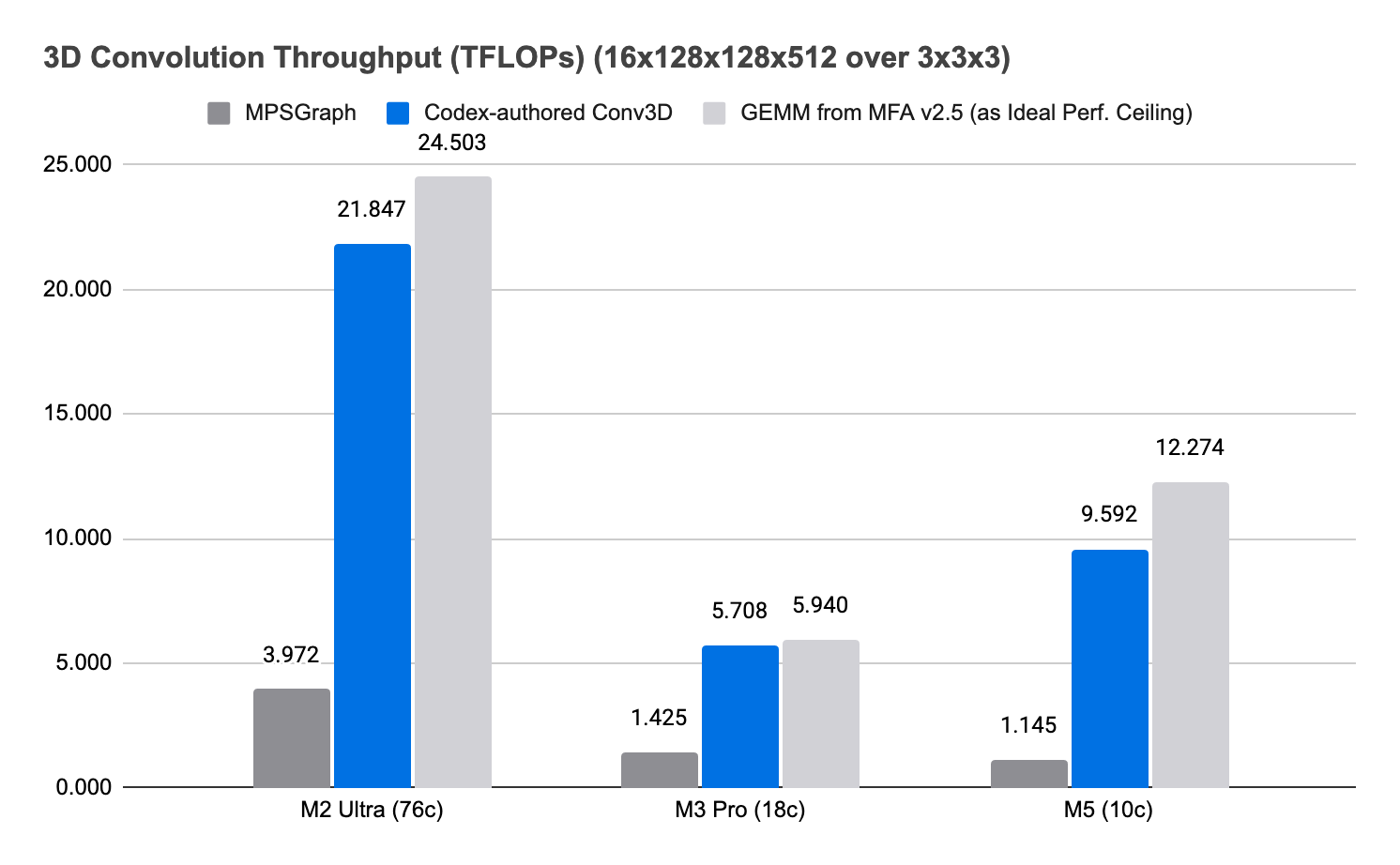
While I still think we can do better with hand-rolled shaders, this kind of work usually takes us weeks, if not months. With Codex, it took 2 days.
It is here. Get used to it.
Yes... YES. All hail the Way of the future. This is very exciting, and thank you for sharing this exciting news - not just the what, but the how/why...